0. 简介
1. 如何安装
使用 pdm 可以直接安装
pdm add easyocr
但安装会有一个问题:无法依赖包 scipy
经过摸索后(方案原帖),找到了解决方案,编辑 pyproject.toml 文件,修改 requires-python
#requires-python = ">=3.10"
requires-python = ">=3.10, <3.11"
2. 如何使用
示例代码如下,就可以读取 jpe 文件里的文字,我这里使用的是 ch_sim 和 en,分别代表简体中文和英文
import easyocr
reader = easyocr.Reader(['ch_sim','en'])
result = reader.readtext('/Users/iswbm/Downloads/house-1.jpg')
print(result)
但亲测后,发现直接运行会报错,报错比较常见,写爬虫的人都知道在代码里加入如下代码
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
完整代码如下
import ssl
import easyocr
ssl._create_default_https_context = ssl._create_unverified_context
reader = easyocr.Reader(['ch_sim','ch_sim'])
result = reader.readtext('/Users/iswbm/Downloads/house-1.jpg')
print(result)
运行后,会下载模型数据(detection model)

如果你没有全局代理,这个过程会非常非常漫长
由于我的浏览器里有代理,于是我就是下载 的 url 打印出来,通过浏览器下载,可以说是秒下载,速度非常快
https://github.com/JaidedAI/EasyOCR/releases/download/pre-v1.1.6/craft_mlt_25k.zip
https://github.com/JaidedAI/EasyOCR/releases/download/v1.3/zh_sim_g2.zip
然后如何把这两个 zip 让 easyocr 自己去解压呢?
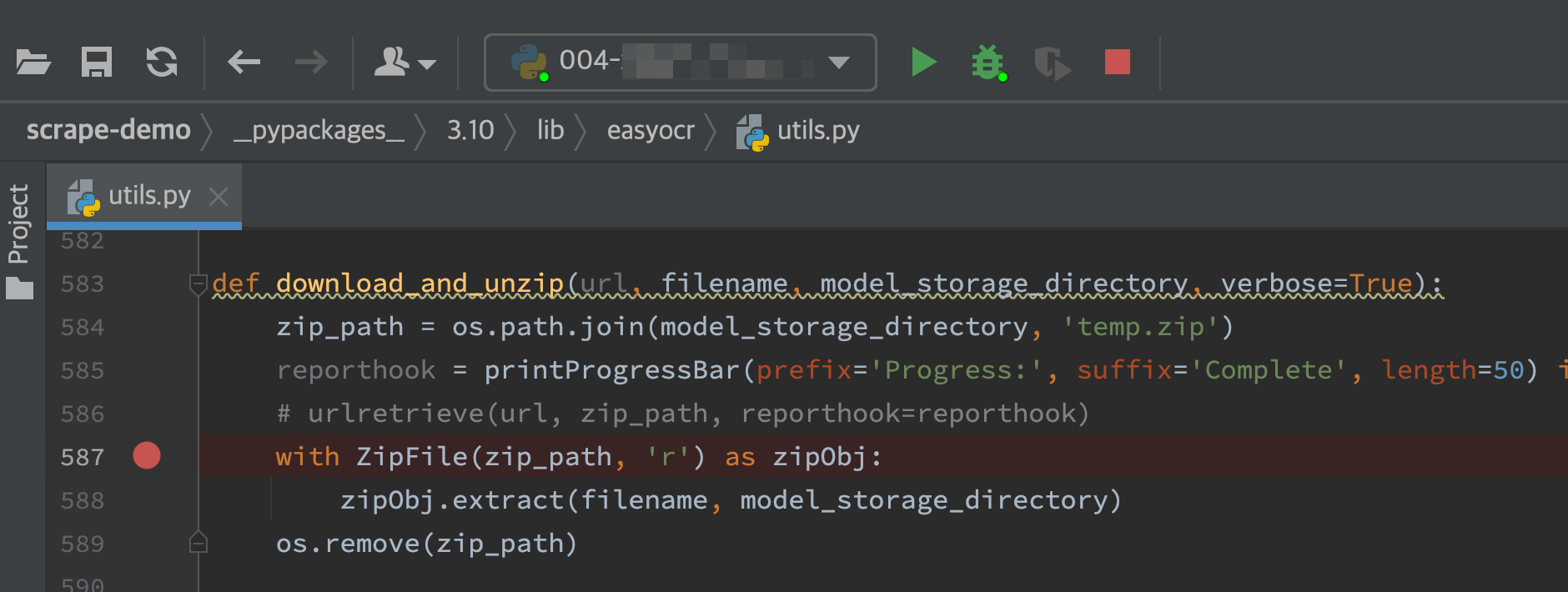
在如下的代码里将 586 行注释,然后在 587 行加断点
- 当第一次进入断点时,执行 cp ~/Downloads/craft_mlt_25k.zip /Users/iswbm/.EasyOCR//model/temp.zip,而后恢复执行
- 当第二次进入断点时,执行 cp ~/Downloads/zh_sim_g2.zip /Users/iswbm/.EasyOCR//model/temp.zip,而后恢复执行
- 当程序可以正常执行后,就把代码复原